



How To Grab Your Medium Engagement Metrics to Excel With One Click?
A free tool to grab your engagement data from Medium.com

As a data nerd, I always seek ways to improve my writing. I'm excited to share my knowledge with you, hoping it will help you enhance your work.
I have already shared a simple method for importing your stories' views, reads, and earnings stats into Excel; please look at this story.
I also wanted to download Medium engagement metrics, claps, and responses, but I didn’t find a straightforward method.
To fix this problem, I created a Chrome browser extension that pulls the data from Medium public GraphQL APIs and saves your data into a CSV file with a click of a button.
Here is what the CSV file looks like on Google Sheets:

Creating a Chrome Browser Extension
I started by creating a directory, MediumGraphQLStoryStats, and added the following empty files:
.
├── ClapCountQuery.json
├── UserStreamOverviewQuery.json
├── background.js
├── cloudberry.png
├── manifest.json
├── popup.html
└── popup.jsThe first file I created was manifest.json. This file defines the metadata and permissions required by your extension.
{
"manifest_version": 3,
"name": "Medium User Story Stats",
"version": "1.0",
"permissions": ["activeTab", "scripting", "downloads", "storage","notifications"],
"background": {
"service_worker": "background.js"
},
"action": {
"default_popup": "popup.html",
"default_icon": "cloudberry.png"
},
"web_accessible_resources": [
{
"resources": ["cloudberry.png"],
"matches": ["<all_urls>"]
}
]
}Next, I wrote UserStreamOverviewQuery.json. This file contains the GraphQL API query to get the list of stories for a given username. This JSON can be extracted using Chrome developer tools.
You need to replace the userId “FinnTropy” on line 4 with your own.
{
"operationName": "UserStreamOverview",
"variables": {
"userId": "FinnTropy",
"pagingOptions": {
"limit": 25,
"page": null,
"source": null,
"to": null,
"ignoredIds": null
}
},
"query": "query UserStreamOverview($userId: ID!, $pagingOptions: PagingOptions) {\n user(username: $userId) {\n name\n profileStreamConnection(paging: $pagingOptions) {\n ...commonStreamConnection\n __typename\n }\n __typename\n }\n }\n fragment commonStreamConnection on StreamConnection {\n pagingInfo {\n next {\n limit\n page\n source\n to\n ignoredIds\n __typename\n }\n __typename\n }\n stream {\n ...StreamItemList_streamItem\n __typename\n }\n __typename\n }\n fragment StreamItemList_streamItem on StreamItem {\n ...StreamItem_streamItem\n __typename\n }\n fragment StreamItem_streamItem on StreamItem {\n itemType {\n __typename\n ... on StreamItemPostPreview {\n post {\n id\n mediumUrl\n title\n firstPublishedAt\n tags {\n id\n }\n __typename\n }\n __typename\n }\n }\n __typename\n }"
} Next, I wrote ClapCountQuery.json. This file contains the GraphQL API query to get the claps and responses for a given PostId.
{
"operationName": "ClapCountQuery",
"variables": {
"postId": null
},
"query": "query ClapCountQuery($postId: ID!) {\n postResult(id: $postId) {\n __typename\n ... on Post {\n id\n clapCount\n __typename\n postResponses {\n count\n __typename\n }\n }\n }\n }"
} Next, I wrote background.js. This script reads the above JSON query files, listens for messages from the popup.js script, and handles data loading and CSV file downloads while sending progress updates to the user interface.
The script has paging logic, so users with hundreds of stories published should be able to get all of them.
// Function to read a JSON file using fetch
async function readJsonFile(filePath) {
try {
const response = await fetch(chrome.runtime.getURL(filePath));
if (!response.ok) {
throw new Error(`Failed to fetch ${filePath}: ${response.statusText}`);
}
const jsonData = await response.json();
return jsonData;
} catch (error) {
console.error('Error reading JSON file:', error);
}
}
// Function to fetch GraphQL data
async function fetchGraphQLData(query, variables) {
const url = 'https://medium.com/_/graphql';
const headers = {
"Content-Type": "application/json",
"Accept": "application/json"
};
const body = JSON.stringify({
query: query,
variables: variables
});
console.log('Request Payload:', body);
try {
const response = await fetch(url, {
method: 'POST',
headers: headers,
body: body
});
if (!response.ok) {
const errorText = await response.text();
throw new Error(`HTTP error! status: ${response.status} - ${errorText}`);
}
const result = await response.json();
return result;
} catch (error) {
showErrorNotification('browser tab must be on https://medium.com/');
console.error('Error fetching GraphQL data:', error);
}
}
// Function to handle pagination and extract "post" items
async function fetchAllPages(query, initialVariables) {
let allPosts = []; // List to store only "post" items
let variables = { ...initialVariables };
let hasNextPage = true;
let progress = 0.;
while (hasNextPage) {
// Fetch current page data
const result = await fetchGraphQLData(query, variables);
if (result && result.data && result.data.user && result.data.user.profileStreamConnection) {
const profileStreamConnection = result.data.user.profileStreamConnection;
// Extract "post" items from the "stream"
const posts = profileStreamConnection.stream
.filter(item => item.itemType.__typename === 'StreamItemPostPreview' && item.itemType.post)
.map(item => item.itemType.post);
progress += posts.length;
sendProgressExtract(progress);
allPosts = allPosts.concat(posts); // Collect posts
// Check for next page in the response
if (profileStreamConnection.pagingInfo && profileStreamConnection.pagingInfo.next) {
const nextPage = profileStreamConnection.pagingInfo.next;
variables.pagingOptions.page = nextPage.page;
variables.pagingOptions.to = nextPage.to;
} else {
hasNextPage = false; // No more pages
}
} else {
sendProgressExtract('Error: Check Username');
console.error('Unexpected response structure:', result);
return null; // Exit if structure is unexpected
}
}
return allPosts; // Return only the list of "post" items
}
// Function to fetch claps and responses for a specific post
async function fetchClapAndResponseCount(query,variables) {
try {
const result = await fetchGraphQLData(query, variables);
if (result && result.data && result.data.postResult) {
const claps = result.data.postResult.clapCount;
const responses = result.data.postResult.postResponses.count;
return { claps, responses };
}
} catch (error) {
console.error(`Error fetching claps and responses for post ${postId}:`, error);
}
return { claps: 0, responses: 0 }; // Return 0 if there's an error
}
// Function to save CSV to a file
function saveCSVToFile(csvContent, filename) {
const blob = new Blob([csvContent], { type: 'text/csv' });
const reader = new FileReader();
reader.onload = function (event) {
const url = event.target.result;
chrome.downloads.download({
url: url,
filename: filename,
conflictAction: 'overwrite',
saveAs: true
}, () => {
console.log(`Downloaded: ${filename}`);
});
};
reader.readAsDataURL(blob);
}
// Function to convert post items to CSV format
async function convertPostsToCSV(posts) {
const headers = ["id", "mediumUrl", "title", "firstPublishedAt", "tags", "claps", "responses"];
const csvRows = [headers.join(",")];
const graphqlData = await readJsonFile('ClapCountQuery.json');
const query = graphqlData.query;
let progress = 0.;
for (const post of posts) {
const { id, mediumUrl, title, firstPublishedAt, tags } = post;
const tagIds = tags.map(tag => tag.id).join(" | "); // Convert tags array to a pipe-separated string
// Fetch claps and responses for each post
const variables = { "postId": id };
const { claps, responses } = await fetchClapAndResponseCount(query, variables);
const publishedAt = convertEpochToDatetime(firstPublishedAt) || '';
const row = [id, mediumUrl, `"${title.replace(/"/g, '""')}"`, publishedAt, `"${tagIds}"`, claps, responses];
csvRows.push(row.join(","));
progress += 100./posts.length;
sendProgressUpdate(progress);
}
return csvRows.join("\n");
}
function convertEpochToDatetime(epochMillis) {
const date = new Date(epochMillis);
return date.toISOString().replace('T', ' ').split('.')[0]; // Converts to 'YYYY-MM-DD HH:MM:SS'
}
// send progress update on percentage of posts updated
function sendProgressUpdate(percentage) {
// Sending a message to popup.js with the current progress
chrome.runtime.sendMessage({ action: 'progressUpdate', percentage: percentage });
}
// send progress update on count of posts extracted
function sendProgressExtract(progress) {
// Sending a message to popup.js with the current progress
chrome.runtime.sendMessage({ action: 'progressExtract', progress: progress });
}
// show error notification
function showErrorNotification(errorMessage) {
chrome.notifications.create({
type: 'basic',
iconUrl: chrome.runtime.getURL('cloudberry.png'), // Replace with a valid path to your extension's icon
title: 'Error',
message: errorMessage,
priority: 2
}, function(notificationId) {
console.log('Notification created with ID:', notificationId);
});
}
// Function to save JSON to a file
function saveJSONToFile(jsonContent, filename) {
const jsonStr = JSON.stringify(jsonContent, null, 2);
const blob = new Blob([jsonStr], { type: 'application/json' });
const reader = new FileReader();
reader.onload = function() {
const url = reader.result;
chrome.downloads.download({
url: url,
filename: filename,
conflictAction: 'overwrite',
saveAs: true
}, () => {
console.log(`Downloaded: ${filename}`);
});
};
reader.readAsDataURL(blob);
}
// Listen for messages from the popup
chrome.runtime.onMessage.addListener((request, sender, sendResponse) => {
if (request.action === 'setUsername') {
(async () => {
try {
const mediumUsername = request.username;
//const graphqlData = await readJsonFile(request.selectedGraphQLFile);
const graphqlData = await readJsonFile('UserStreamOverviewQuery.json');
// Update the variables with the received Medium username
graphqlData.variables.userId = mediumUsername;
const query = graphqlData.query;
const variables = graphqlData.variables; // This now includes the updated userId
// Fetch all pages of GraphQL data
const data = await fetchAllPages(query, variables);
if (data) {
// Convert posts to CSV format
const csvContent = await convertPostsToCSV(data);
// Save content to a CSV file
const filename = 'myposts.csv';
saveCSVToFile(csvContent, filename);
// Save JSON to a file
//const filename = `graphql_output_${request.selectedGraphQLFile}`;
//saveJSONToFile(data, filename);
// Send response back to the popup
sendResponse({ success: true });
}
} catch (error) {
console.error('Error processing GraphQL request:', error);
sendResponse({ success: false, error: error.message });
}
})();
return true; // Keeps the message channel open for async sendResponse
}
});I wanted a simple UI where users could enter their Medium username and click a button to fetch their stories' engagement data. The web page has two progress bars, one for the extract process and another for getting the engagement metrics for each story.
For that, I created popup.html page
<!DOCTYPE html>
<html>
<head>
<title>Medium Username Input</title>
<style>
#progress-bar-container {
width: 100%;
background-color: #f3f3f3;
border: 1px solid #ccc;
margin-top: 20px;
}
#progress-bar {
width: 0%;
height: 20px;
background-color: #4caf50;
text-align: center;
color: white;
line-height: 20px;
}
</style>
<script src="popup.js" defer></script>
</head>
<body>
<label>Fetch Medium Stories with Stats For User</label>
<input type="text" id="medium-username" placeholder="Enter Medium username" />
<button id="submit-username">Submit</button>
<h2>Extract Posts</h2>
<div id="progress-bar-container">
<div id="progress-extract"></div>
</div>
<h2>Get Posts Stats</h2>
<div id="progress-bar-container">
<div id="progress-bar">0% done</div>
</div>
</body>
</html>and popup.js script that handles communication with background.js functions.
document.addEventListener('DOMContentLoaded', function () {
document.getElementById('submit-username').addEventListener('click', function () {
const username = document.getElementById('medium-username').value;
if (username) {
// Send the username to the background script
chrome.runtime.sendMessage({ action: 'setUsername', username: username });
} else {
alert('Please enter a Medium username.');
}
});
// Listen for messages from background.js
chrome.runtime.onMessage.addListener(function (request, sender, sendResponse) {
if (request.action === 'progressUpdate') {
const percentage = request.percentage;
updateProgressBar(percentage); // Update the UI with the new progress
}
});
// Function to update the progress bar or any other UI element
function updateProgressBar(percentage) {
const progressBar = document.getElementById('progress-bar');
if (progressBar) {
// Limit the percentage to one decimal place
const formattedPercentage = percentage.toFixed(1);
// Update the width and text content of the progress bar
progressBar.style.width = formattedPercentage + '%';
progressBar.textContent = formattedPercentage + '% done';
}
}
// Listen for messages from background.js
chrome.runtime.onMessage.addListener(function (request, sender, sendResponse) {
if (request.action === 'progressExtract') {
const progress = request.progress;
updateProgressExtract(progress); // Update the UI with the new progress
}
});
// Function to update the progress extract UI element
function updateProgressExtract(progress) {
const progressBar = document.getElementById('progress-extract');
if (progressBar) {
progressBar.textContent = progress;
}
}
});Finally, I uploaded the cloudberry.png logo file, which I purchased license rights to use in my projects from Vectorstock.
You can use your own logo file; rename it to cloudberry.png since it is referenced in the code.
With these files in place, I started testing this new Chrome Browser Extension
Load and Test the Extension
Open Chrome, go to
chrome://extensions/.Enable "Developer mode" in the top-right corner.
Click "Load unpacked" and select the directory where your extension is located. In my case, it was the MediumGraphQLStoryStats folder.
You should see the extension “Medium User Story Stats 1.0” like the one on the left:
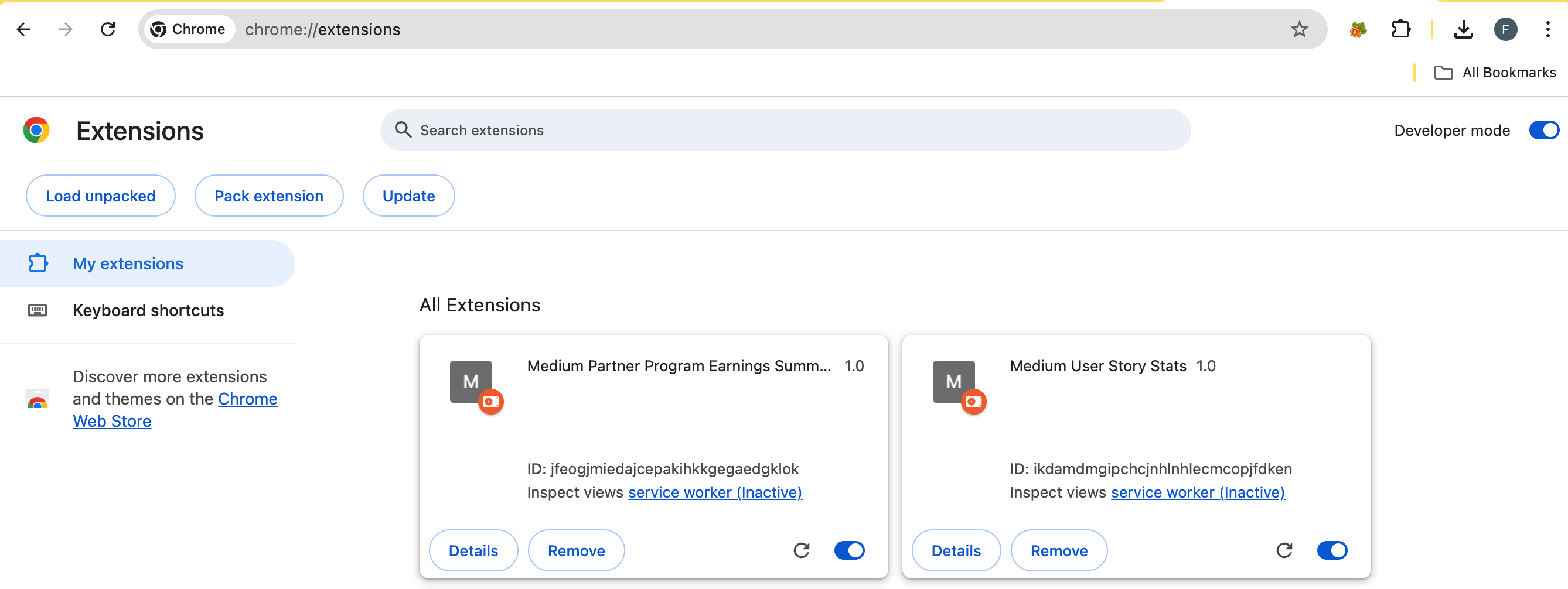
You need to enable the extension using the toggle on the bottom corner.
Your extension should now appear in the toolbar or as an icon in Chrome. The Cloudberry icon I use is visible on the right side of the address bar.
Next, go to the https://medium.com website and go to your Profile page from the top right corner menu (with your profile picture) - in my case, it will redirect to https://medium.com/@FinnTropy
@FinnTropy is my Medium username.
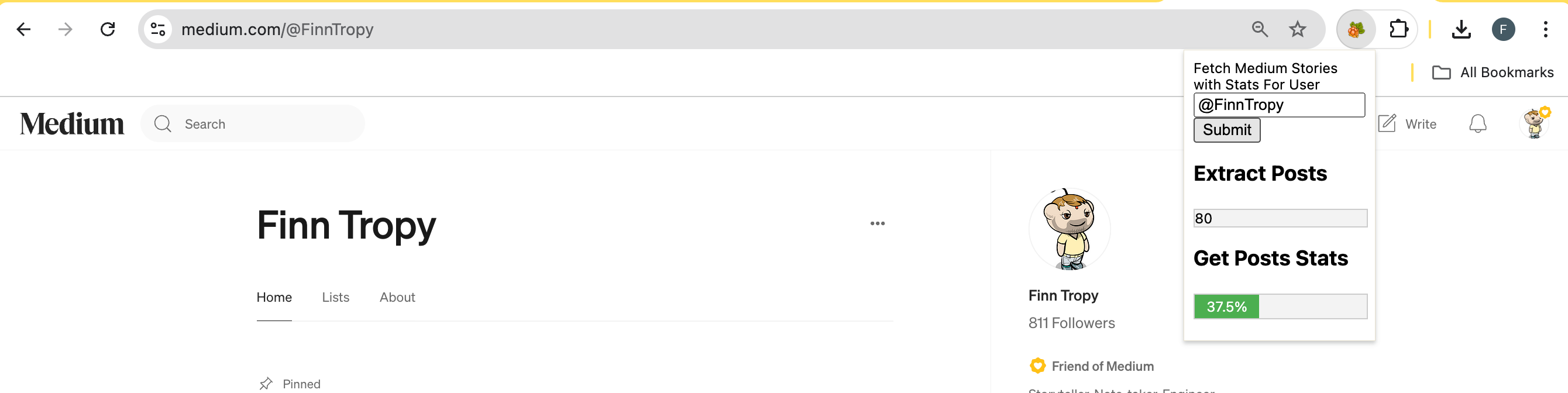
Now click the Cloudberry icon. A small pop-up window will open, asking you to enter your Medium username (any valid username should work).

Click submit, and the Chrome browser extension will first extract information on all of your posts. You can see the counter increasing in the Extract Posts field.
Then, it will get the posts' stats, and you will see the percentage increase from 0% to 100%.
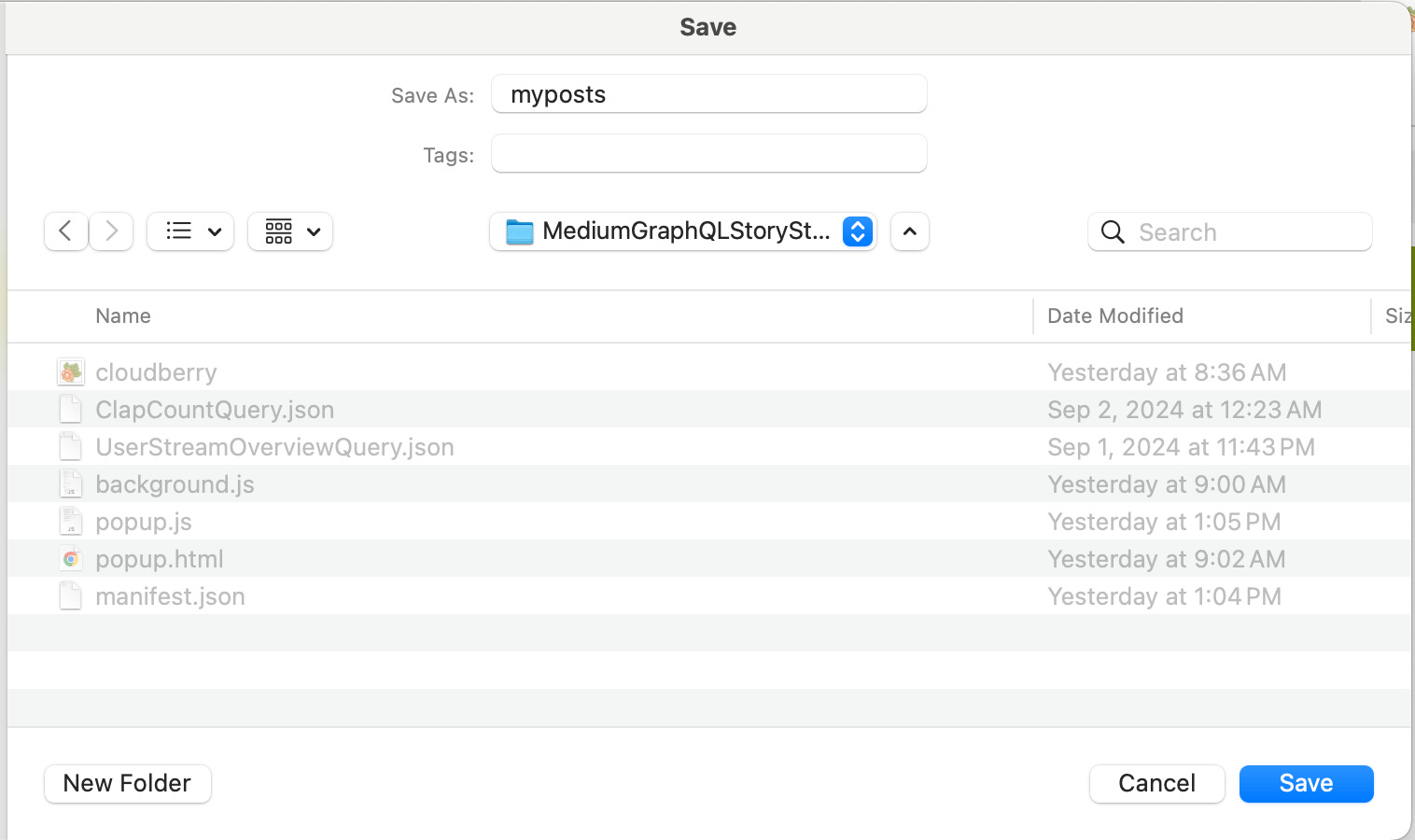
Finally, you will get a popup window asking where to store the “myposts.csv” file like below:
Conclusion
I built a simple Google Chrome Browser extension to grab my Medium Engagement metrics for my stories into a spreadsheet.
This helps me to track which stories have performed over time and where I should focus my time.
I would love to hear your comments.
Did this save some time grabbing the metrics?
What other data would you be interested in getting?
PS. You can grab free access to “Top Authors Dashboard” from here:
Love it but I’m curious why you didn’t extend the earnings extension
First of all, love the rebrand!
Second of all, I'm looking forward to going through this because this is what I wanted to tinker with when it came to metrics. I'll have to follow up later, but it's my bedtime!